
Random Forest
Table Of Contents
- Introduction
- Why do we need Random Forest?
- Bagging(Bootstrap Aggregation)
- Decision Tree VS Random Forest.
- Advantages and disadvantages of Random Forest.
- Conclusion.
INTRODUCTION
Random Forest (RF) is a popular supervised machine learning algorithm used for both classification and regression problems. The term ‘Forest’ in Random Forest refers to multiple decision trees. It is based on the concept of ensemble learning that combines multiple base models (decision trees for RF) to improve the model's performance. Random Forest contains a number of decision trees on various subsets of the given dataset and takes the majority vote to improve the predictive accuracy of that dataset.
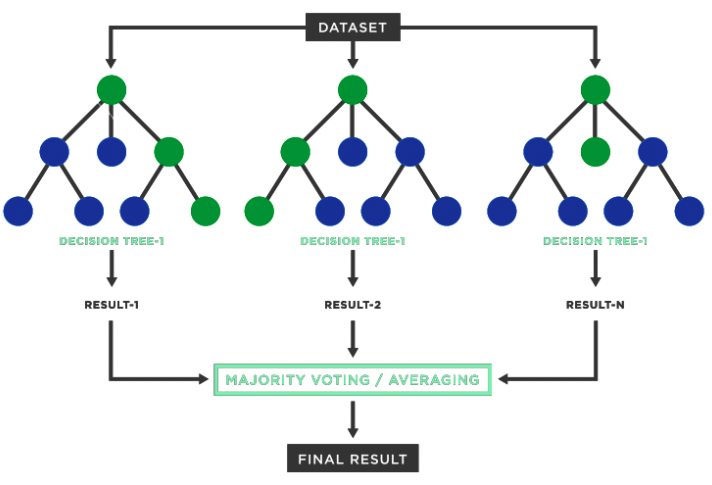 Figure-(1)
Figure-(1)
For example, if you want to buy a phone, it is unlikely that you will simply purchase the phone recommended by a single person. Instead, you will probably seek advice about the phone from different experts. Based on the majority vote among the experts' recommendations, you will decide to purchase a phone.
Random forest works exactly the same. Instead of being dependent on a single decision tree, it takes the predictions from different decision trees and based on the majority votes of predictions, it predicts the final output.
Why do we need Random Forest?
Even though decision tree is simple and fast, it’s a greedy algorithm. It prioritizes optimizing the node split at hand, ignoring the overall impact of that split on decision tree. Being a greedy algorithm makes it prone to overfitting.
Overfitting is a condition which results in low bias and high variance conditions. Decision tree has a low bias meaning it performs well or predicts with good accuracy on the training data but it has a high variance and doesn’t perform well or predict with good accuracy on the testing or unseen data.
Random Forest algorithm helps us to prevent the condition of overfitting. It helps us to reduce the variance from high to low. Hence we get better accuracy on the unseen or testing data.
But, how does the random forest reduce the variance…? How, does the random forest solve the problem of overfitting….?
The answer lies in the ‘Bagging’ technique used by the random forest algorithm.
BAGGING
Let us understand how the random forest works for a given dataset and understand the bagging technique.
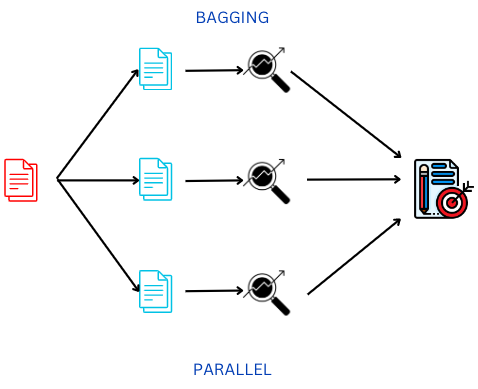 Figure-(2)
Figure-(2)
Bagging is nothing but a short form for ‘Bootstrap Aggregation’. It is a parallel process in which different base models(Decision trees in random forest) are trained independently. The outputs from different base models for the testing/unseen data are then ‘aggregated’ into one final result.
Since different base models(Decision trees) output/predictions are combined to obtain a single more powerful random forest model, Bagging is also an ensemble technique.
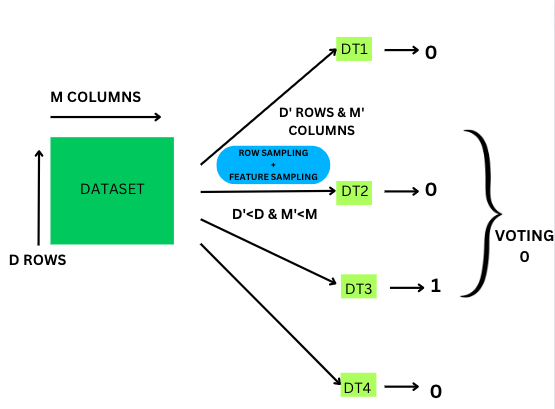
Suppose we have a training dataset with ‘d’ no. of rows and ‘m’ no. of features/columns. The multiple base models in Random Forest are combinations of the decision trees or we can say ensembled decision trees.
Let’s say we have 4 Decision Trees(DT1, DT2, DT3 and DT4) in the random forest.
The decision tree in the random forest has d’ rows and m’ features/columns such that d’<d and m’<m.
Every decision tree in the random forest is provided with a sample/subset of the entire dataset. The sample/subset of the dataset provided to each decision tree is a combination of both row sampling and feature sampling with replacement(‘bootstrap samples’ in bagging). Since we are performing sampling with replacement on the training dataset, each of the decision tree is trained independently on a smaller random dataset. Some of the data points provided to a particular decision tree can be repeated in the other decision trees.
Finally, after completing the training process, the outputs for the testing data from different decision trees are ‘aggregated’ into one final result. In classification problems ’aggregation’ means majority vote classifier which picks up the most common class predicted among the decision tree.
In, the above example since 3 out of 4 DT predicted as class ‘0’, so by majority vote classifier, the random forest predicts the output as ‘0’.
In regression problems, we literally average out the outcomes/predictions for ‘aggregation’.
Given each base model(decision tree) is trained on a different dataset(bootstrap samples) they are experts in the random subset of data provided to them. Every base model will make different mistakes and have distinct errors and variances while predicting for the testing or unseen data. The step of ‘aggregation’ in Random Forest considers the outcomes from all different base(decision tree) models, which helps us reduce both the error and variance.
Basically, we are combining the predictions from multiple weak base learners(each DT) to get a single and more powerful predictive model(RF). This is exactly how random forest reduces the variance from ‘high’ to ‘low’ and increases the predicting power/accuracy on the testing or unseen dataset.
Decision Tree VS Random Forest
| Decision Tree | Random Forest |
|---|---|
| 1. Single tree model. | 1. Ensemble of decision trees. |
| 2. Decision tree suffers overfitting when grown to maximum depth. | 2. Random forest prevents overfitting through bagging technique. |
| 3. It is faster in computation. | 3. It is relatively slower due to its complexity. |
| 4. A decision tree takes a dataset with features as input and formulates rules to make predictions | 4. Observations are randomly chosen, and a decision tree is constructed, followed by averaging the result. |
Advantages and disadvantages of Random Forest:
| Advantages | Disadvantages |
|---|---|
| Good Results: Can often produce good results without extensive hyperparameter tuning. | Real-Time Predictions: Slower in making predictions compared to decision tree and not ideal for time-sensitive tasks. |
| Handling Capability: Random forest handles complex dataset or high dimensional data with a number of features. It also handles missing values. | Computational Complexity: Random forest is computationally expensive while dealing with a large tree or complex dataset leading to longer training time. |
| Overfitting Prevention: Combining multiple decision trees prevents overfitting and helps us achiece low variance. | Black Box Model: Random forest is a black box model since it doesn't provide clear explanations for its predictions, not suitable for scenarios requiring interpretability and explainability. |
| Flexibility: Can be used for both regression and classification problems. |
Conclusion
Random Forest is a powerful and versatile supervised machine-learning algorithm used for both regression and classification problems. It is based on the bagging technique and uses an ensemble of decision trees through which it solves the problem of overfitting and helps us achieve lower variance. Random Forest is able to handle high-dimensional dataset having numerous features as well as handles missing values in the dataset. Its limitations include computational complexity, lack of interpretability, and not suitable for real-time predictions. Nevertheless, it will always remain a popular choice in machine learning.