DECISION TREE
Decision trees are tree-based models which are widely used supervised learning algorithms for both classification and regression problems (CART).
Decision trees in a way act like human brains while making a decision. The logic in decision tree is simple to understand as it is just a structured tree with a bunch of if-else statements. Due to the straightforward implementation and interpretation, decision trees are an excellent choice for a newbie in the field of machine learning.
In this blog, we will discuss the definition of decision tree, different terminologies associated with it, examples and the complete process of decision tree algorithm. We will also look at the advantages and limitations of a decision tree.
Introduction
- Decision tree is the graphical representation of all the possible outcomes to a problem/decision based on given conditions.
- It is called a decision tree since it’s similar to a tree consisting of a root node containing the entire data which then splits into branches, internal nodes (decision nodes) representing the features of a dataset and leaf nodes are the final outcomes. It is just like a tree which grows from the root and starts expanding its branches and have leaves.
- A decision tree is basically a bunch of if-else conditions and based on the answer (Yes/No) it further split the tree into sub-trees.
Let us try and understand a simple example of decision tree:
Let’s say you are given a problem statement where you have to predict whether a person is fit or unfit (Output variable).
If we construct the decision tree for solving a classification problem of whether the person is fit or unfit given the different input features like Age, eating habits and physical activity we would get something like this:
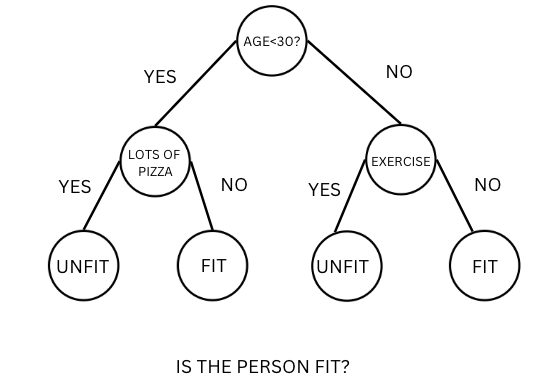
Figure-(1)
The root node here is the question Age<30 and decision nodes are Eats a lot of pizzas, Exercises or not and the leaf nodes are the final outcomes of whether the person is fit or unfit.
To predict the output(fit/unfit) for any data we will traverse from the top (root node) to bottom (leaf node) based on the if-else conditions of the features in the data to conclude whether the person is fit or unfit.
Let’s understand the different terminologies used like root node, decision node and leaf node in the next section.
Decision Tree Terminologies
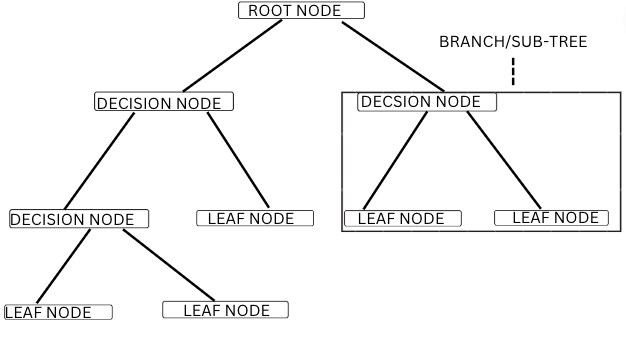
-
Root Node: The decision tree starts from the root node which then gets divided into two or more homogeneous sub-tree. It represents the entire population dataset. In the above example of decision tree, the root node is the AGE<30.
-
Decision Node: After splitting the root node, we get the decision nodes. The node Eat’s a lot of pizzas and Exercise are the decision nodes.
-
Leaf Node: Leaf nodes are the terminal nodes that represent the final outcome and after which further splitting is not possible. It is a pure node as it consists of data points that entirely belong to one class (either 0 or 1) like fit or unfit in the above example.
-
Parent/Child Node: The root node is the parent node and all other nodes that branched from it are called child nodes.
-
Branch/Sub-Tree: A branch or a sub-tree is formed by splitting the tree/node.
-
Splitting: Splitting is the process of dividing the root node or decision node into sub-nodes based on some conditions.
-
Pruning: Pruning is the process of removing unwanted branches from the tree to avoid overfitting.
One thing you must be wondering in the above example how do we select feature age as the root node and how we decide that the condition age<30 will be used for splitting the data. Why the decision nodes are here for features like pizza and exercise instead of age?
The answer lies in understanding terminologies like Entropy and Gini impurity, which will be used to determine the purity of split and Information gain that help us decide which features will be used for splitting the data.
In my next blog, we will focus on understanding these terminologies.
Decision Tree Algorithm
The complete steps in building a decision tree are:
- Initialize the tree: Start with a root node containing the entire dataset.
- Finding the best split: Choose the feature in the dataset using criteria such as Entropy, Gini-Impurity and Information Gain for finding the best feature to split the data.
- Creating decision nodes: Split the dataset into subsets based on the answer(Y/N) of the selected feature, creating decision nodes for each subset.
- Repeat the process: Recursively repeat steps 2-3 for each decision node, selecting the next best feature for splitting until we reach the final leaf nodes where we cannot split further.
- Pruning the tree: Removing the unwanted branches/nodes that do not significantly improve the predicting power of the tree to avoid overfitting is called pruning. Overfitting is a condition in which the model performs well on the training data but fails to generalize well or doesn’t perform well on the testing data.
- Predictions: Using decision tree to classify new data based on the feature values, following the path from root node to leaf node which gives the final outcome or predicted class (0/1) of the new data.
Advantages
- Decision trees can handle missing values reducing the need for data-cleaning techniques.
- Decision trees are non-parametric, meaning they don’t make any assumptions for the distribution of data, making them suitable for solving both linear and nonlinear relationship problems between the output and input variables.
- Decision trees are used for both classification and regression problems. It is easy to understand and interpret, making them an ideal algorithm for visualizing and explaining complex decision-making processes.
Limitations
- Overfitting: Decision trees are prone to overfitting. When we have a large real-life dataset containing numerous features, the decision tree will be complex in nature with many splits, making it prone to overfit.
- Instability: Decision trees can be unstable, meaning small variations in the data can give a very different decision tree.
- Bias: Decision trees can be biased in splitting features with a larger number of values than the features with less value, giving us inaccurate predictions.
In my next blog, we will focus on understanding the concept behind feature selection and purity of split concepts like Entropy, Gini Index and Information gain clearly with an example. We will also look at how a decision tree is created for a sample dataset.