
INTRODUCTION
In this blog, we will create and visualize a decision tree for a simple tennis dataset, predicting whether the person will play based on different weather conditions."
Importing Necessary Packages:
import pandas as pd
import numpy as np
Reading and seeing the data:
tennis=pd.read_csv('PlayTennis.csv')
tennis
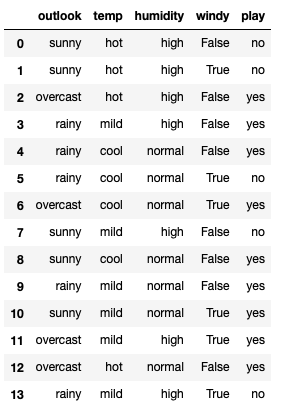
Since decision tree is an algorithm that uses mathematical concepts like entropy,gini impurity and information gain we have to convert all the categorical features to numerical variables.
For this we use labelencoder from sklearn library. Labelencoder converts all the different categories of the categorical feature to a numeric variable. For example it converts the categories sunny,overcast,rainy of categorical feature outlook into 0,1 and 2 which is random in nature but unique to each category.
Importing labelencoder from sklearn library:
from sklearn.preprocessing import LabelEncoder
#Creating an object of LabelEncoder class
LB=LabelEncoder()
#Using loop for labelencoding all categorical features/columns.
for i in tennis.columns:
tennis[i]=LB.fit_transform(tennis[i])
print(tennis)
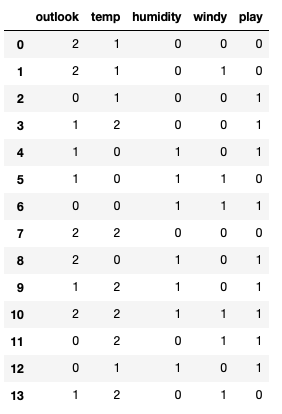
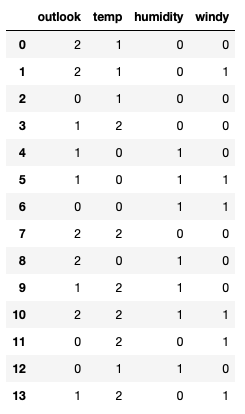
Splitting the X(Features/Input) and Y(Output/Target):
x=tennis.drop('play',axis=1)
y=tennis['play']
print(x)
print(y)

Importing the decision tree and fitting/training the decision tree model:
from sklearn import tree
# Using Entropy as a criteria for splitting the tree.
clf=tree.DecisionTreeClassifier(criterion='entropy')
clf.fit(x,y)
DecisionTreeClassifier(criterion='entropy')
Visualising the decision tree:
y_pred = clf.predict(x)
tree.plot_tree(clf)
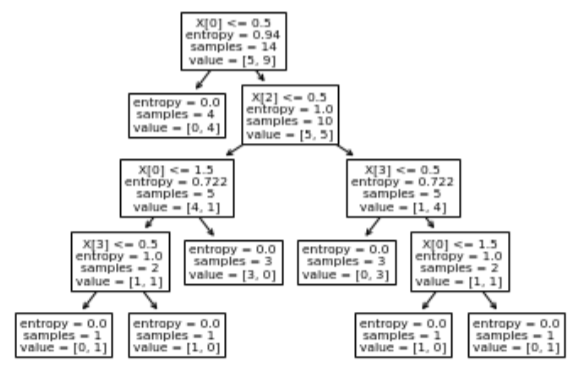
In the above graph X[0]=OUTLOOK,X[1]=TEMP,X[2]=HUMIDITY,X[3]=WINDY,VALUE=[5,9] means 5 No and 9 Yes for the Output play.
Since we have used all the features (X) for training data, we don't have any test data. Therefore, we will make the model predict on the training data."
y_pred = clf.predict(x)
Evaluating model performances:
y_pred == y

It's clear that the model has predicted everything correctly.